안녕하세요~ 동사힐입니다. 😊
오늘은 비트코린 차트를 머신러닝으로 예측하는 방법을 알 수 있는 책인 금융 전략을 위한 머신러닝 후기를 적어보고자 합니다.
한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평이니, 참고 바랍니다.
1. 금융 전략을 위한 머신러닝 - 금융과 머신러닝의 완벽한 만남


금융 전략을 위한 머신러닝의 원제목은 Machine Learning and Data Science Blueprints for Finance입니다. 책을 소개하는데 영어 원제목을 먼저 설명하는 이유는 영어 제목이 이 책의 특성을 온전하게 설명해주기 때문인데요. 실제로 이 책은 금융에 활용할 수 있는 머신러닝과 데이터 과학의 청사진을 구체적으로 제시하는 책입니다.
단순히 금융과 관련된 사례나 코드 예제만 제공하는 것이 아니라 머신러닝과 데이터 과학과 관련된 다양한 학습 모델을 제공하고 있고, 다양한 모델을 7단계 문제 접근 방법 툴을 활용해서 공통적으로 적용해볼 수 있도록 설명하고 있습니다.
그뿐만 아니라 기존의 머신러닝 & 데이터과학 책에서는 주로 예제를 사이킷런 등에 포함되어 있는 기본 예제로 설명하는 경우가 대다수인데, 이 책은 캐글(https://www.kaggle.com/)의 다양한 예제 등을 활용하고 있습니다. 실제 예제의 파일들은 주로 FRED(Federal Reserve Economic Data, 미 연방 준비 은행 경제 데이터)나 야후 파이낸스, 비트스탬프 등 실제 미국의 주요 경제 지표를 확인할 수 있는 실질 데이터를 가지고 분석합니다. 이러한 예제만 보더라도, 실무에서 충분히 활용 가능한 예제임을 알 수 있습니다.
이 책에서 예측하는 독자층은 헤지 펀드, 투자 및 소매 은행, 핀테크 회사에서 일하는 데이터 과학자, 데이터 엔지니어 퀀트 연구원, 머신러닝 설계자 또는 소프트웨어 엔지니이업니다. 역으로 말하면 이러한 금융 핀테크 기업에서 데이터 전문가 직무를 갖기 원하는 주니어 개발자에게 실무 예제를 경험해볼 수 있는 책이라고 볼 수 있습니다.
https://docs.google.com/spreadsheets/d/1zpLFAPZ8NA6V09JUUU66g_lvpVra24B_ZTDHunM2O8c/edit?usp=sharing
[한빛미디어] 머신러닝·딥러닝 도서 선택 가이드(update 21-12-27)
딥러닝/머신러닝(21-11-25) 분류,알고리즘,알고리즘,알고리즘 주 활용 분야 학습 방법,지도학습,지도학습,지도학습 입력의 규칙성(문제?),회귀,회귀,회귀 특징 추론/확률,추론/확률,추론/확률 선행
docs.google.com
다만, 이 책의 난이도는 상당히 높습니다. 한빛미디어에서 제작한 '[한빛미디어] 머신러닝·딥러닝 도서 선택 가이드'를 보면 이 책의 난이도는 무려 7입니다. 위 도서선택가이드에서 머신러닝, 딥러닝 관련 책이 총 61권인데, 이중 난이도 7이상의 책은 13권뿐입니다. 이 정도면 상당한 난이도라고 할 수 있습니다.
하지만 난이도에 겁먹을 필요는 없습니다. 적어도 파이썬을 어느 정도 다뤄본 독자라면 충분히 이해하고 파악할 수 있습니다. 만약 파이썬을 다뤄보지 않았더라도, R 등을 활용해서 데이터 분석을 해본 독자도 충분히 접근 가능합니다.
저는 오히려 이 책을 제대로 활용하기 위해서 필요한 지식은 컴퓨터 언어 관련 지식은 아니라고 생각합니다. 솔직히 말씀드리면 이 책에서는 아나콘다를 설치하여 주피터 노트북으로 코드를 실행하라고 나와 있는데, 예제 코드를 보고 주피터 노트툭보다 구글 코랩을 활용하면 훨씬 수월하게 예제 코드를 모두 실행할 수 있습니다.
구글 코랩은 기본 세팅이 이미 다 되어 있고, 구글의 GPU를 활용하여 연산하기 때문에 노트북으로도 충분히 머신러닝을 할 수 있는 좋은 프로그램입니다. 구글 코랩에서 데이터를 불러오기만 할 수 있으면 프로그래밍 언어적으로 필요한 능력은 모두 끝났다고 생각합니다.
그것보다 더 요구되는 역량은 바로 머신러닝과 관련된 지도 학습, 비지도 학습, 강화 학습 등의 모델링과 알고리즘에 대한 이해도입니다. 예를 들어 이 책에서 지도 학습과 관련하여 선형 회귀부터 정규화 회귀, 로지스틱 회귀, 서포트 벡터 머신, K-최근접 이웃, 선형 판별 분석, 분류 트리, 회귀 트리, 앙상블 모델 등 다양한 모델을 소개하고, 실제로 데이터로 분석을 합니다. 이런 개념들을 이해하고, 어떻게 분석하고 효과성을 판별하는지에 대해서 정확히 알아야, 실제로 책에서 비트코인 거래 전략 알고리즘에서 다양한 모델 중에서 앙상블 모델의 랜덤 포레스트 모델을 선정했는지 이해할 수 있습니다. 이는 앞에서 말씀 드린 이 책의 기본 구조가 7단계 문제 접근 방식으로 인해 두드러지는 특징인데요. 예제 연습이나 실무에서도 바로 활용할 수 있도록 하기 위함인데요, 특히 모델 평가와 모델 튜닝 구조는 머신러닝에서 매우 필수적으로 학습해야 할 부분이며, 이 책이 지닌 가장 큰 매력이라고 생각합니다.
또한 머신러닝, 딥러닝에 관심이 많은 독자분이라면 '[한빛미디어] 머신러닝·딥러닝 도서 선택 가이드'를 참고하시면 학습하는데 큰 도움이 될 것입니다.
그러면 구체적으로 이 책의 특징을 살펴보겠습니다.
2. 독자 맞춤형 예제 소스 제공
https://gitlab.com/inspro9/hanbit_mlfi
Hahnsang Kim / hanbit_mlfi
GitLab.com
gitlab.com
먼저 이 책의 보물이라고 할 수 있는 예제 소스와 설명이 담긴 깃입니다. 저는 처음의 예제 소스를 책에서 못 찾아서 한빛미디어 담당자에게 메일까지 보냈었는데요. 메일 보내고 30분도 안되어서 바로 친절하게 답해주셔서 정말 감사한 마음이었습니다. 사실 이 예제 소스 주소는 책 표지 뒷면에 나와 있음에도 불구하고, 저의 주의 부족으로 찾지를 못했었죠.

Notebooks by Machine Learning Types
1. Supervised Learning- Regression and Time series Models
- Stock Price Prediction
- Derivative Pricing
- Investor Risk Tolerance and Robo-advisors
- Yield Curve Prediction
2. Supervised Learning- Classification Models
3. Unsupervised Learning- Dimensionality Reduction Models
- Portfolio Management - Eigen Portfolio
- Yield Curve Construction and Interest Rate Modeling
- Bitcoin Trading - Enhancing Speed and accuracy
4. Unsupervised Learning- Clustering
5. Reinforcement Learning
6. Natural Language Processing
- NLP and Sentiments Analysis based Trading Strategy
- Digital Assistant-chat-bots
- Documents Summarization
3. 7단계 문제 접근방법 템플릿 제공
이 책은 파이썬을 사용하여 실전에 활용 가능한 문제를 제시하고 풀어 나갑니다. 또한 7단계 문제 접근방법(문제 정의 - 데이터 불러오기 - 데이터 분석 - 데이터 준비 - 모델 평가 - 모델 튜닝 - 모델 확정)의 템플릿을 제시합니다. 이 템플릿을 이용하여 새로운 머신러닝 문제에 쉽게 접근할 수 있습니다. -금융 전략을 위한 머신러닝 5쪽
금융 전략을 위한 머신러닝은 파이썬을 기반으로 실무에서 바로 활용할 수 있는 여러 사례들을 다양한 머신러닝 모델을 활용하여 풀어나갑니다. 특히 7단계 문제 접근 방법을 제시하고, 이를 19가지 사례 전부에 적용합니다. 이를 통해 독자로 하여금 실무에 쉽게 응용할 수 있도록 만들고 있습니다.
특히 모델 평가와 모델 튜닝 부분은 머신러닝을 학습하는 주니어 개발자나 실무에서 일하는 현직 전문가에 큰 인사이트를 줄 것이라고 생각합니다. 그만큼 매우 활용도가 높으면서 깊이 있는 내용을 다루고 있습니다.
4. 비트코인, 주가 예측 그리고 챗봇까지 금융의 전 분야를 아우르는 19가지 사례 제공
코로나19 팬데믹 이후 디지털 트랜스포메이션과 AI 트랜스포메이션 바람이 기업에 불면서 동시에 머신러닝과 딥러닝 또한 혹독한 겨울을 지나 지금 다양한 영역에서 활용되고 있습니다. 이에 따라서 많은 실무자나 주니어 개발자들이 머신러닝과 딥러닝을 학습하고 있는데요. 머신러닝을 다른 산업군보다 빠르게 활용했던 영역이 바로 금융입니다. 굳이 미국의 켄쇼를 언급하지 않아도, 국내에서도 상당수의 증권나 펀드 운용사에서 인공지능 AI를 활용해서 운용하는 펀드가 많습니다. 그뿐만 아니라 챗봇도 많이 운용하고 있구요.
금융 분야에서 머신러닝을 많이 활용할 수 있는 가장 큰 이유는 바로 방대한 데이터를 엄청나게 빠른 속도로 만들어내고, 또 신속하게 의사결정을 내려서 흔들림없이 내린 결정을 지속해 가야 하기 때문입니다. 이런 금융 분야에서 구체적으로 활용할 수 있는 금융 사기 탐지, 비트코인, 주가 변화 예측, 포트폴리오 구성, 챗봇 시스템까지 머신러닝을 통해 활용할 수 있는 다양한 사례를 금융 전략을 위한 머신러닝에서는 사례로 제시하고 실제로 구현합니다.
그뿐만 아니라 각 장의 끝에는 이와 비슷한 사례의 연습 문제를 제시하여 독자로 하여금 스스로 고민하고 응용할 수 있도록 구체적이고 실질적인 아이디어를 함께 제시합니다.
- 금융, 핀테크 분야 전문가로서 머신러닝을 학습하고 싶은 독자
- 머신러닝 학습자로서 보다 실질적인 구체적인 사례를 연습하고 싶은 독자
- 금융 기업의 데이터 전문가로 취업을 준비하는 독자
- 자신의 머신러닝, 데이터 과학 관련 분야를 금융 분야와 연결시켜 확장시키고 싶은 독자
이러한 독자들에게는 매우 소중한 책이 될 것이라고 생각합니다.
5. 비트코인 차트 예측 예제
https://gitlab.com/inspro9/hanbit_mlfi/-/blob/main/Ch6_SLC/CS3BTS/BitcoinTradingStrategy.ipynb
Ch6_SLC/CS3BTS/BitcoinTradingStrategy.ipynb · main · Hahnsang Kim / hanbit_mlfi
GitLab.com
gitlab.com
금융 전략을 위한 머신러닝 책 본문 216쪽부터 나와 있는 실전 문제 비트코인 거래 전략의 코드 중 제가 실행한 일부 코드만 공유하고자 합니다. 금융 전략을 위한 머신러닝을 학습하는 독자들에게 조금이나마 도움이 되었으면 합니다.
from google.colab import drive
drive.mount('/content/drive')
# load dataset
dataset = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/bitstampUSD_1-min_data_2012-01-01_to_2021-03-31.csv')먼저 저는 구글 코랩을 활용해서 코드를 실행했습니다. 위 코드는 저의 구글드라이브를 구글 코랩에 가상으로 마운트하는 명령어이구요. #은 주석이고, 그 다음줄은 데이터를 읽어내는 명령어입니다. 아무 생각없이 예제 소스를 그대로 복붙하면 실행이 안됩니다.
구글 코랩에서 파일의 폴더 모양을 클릭하신 후에 구글드라이브에 원하는 데이터의 경로 복사 기능을 활용해서 경로를 복사해주시면 데이터 파일을 읽어냅니다.

구글 코랩을 처음 활용하던 제가 처음에 많이 헤매던 부분이어서, 저처럼 파이썬을 잘 모르는 분들도 구글 코랩에서 경로 복사 기능만 이해하셔도 충분히 예제 소스를 이상없이 테스트해볼 수 있습니다.
import matplotlib.pyplot as plt처음에 matplotlib을 plt로 지정한 후에 다음의 메서드로 비트코인 그래프를 그렸습니다.
dataset[['Weighted_Price']].plot(grid=True)
plt.show()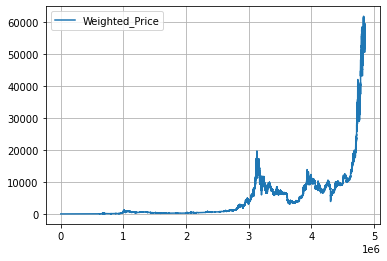
히스토그램도 다음 코드로 구현했습니다.
# histograms
dataset.hist(sharex=False, sharey=False, xlabelsize=1, ylabelsize=1, figsize=(12,12))
plt.show()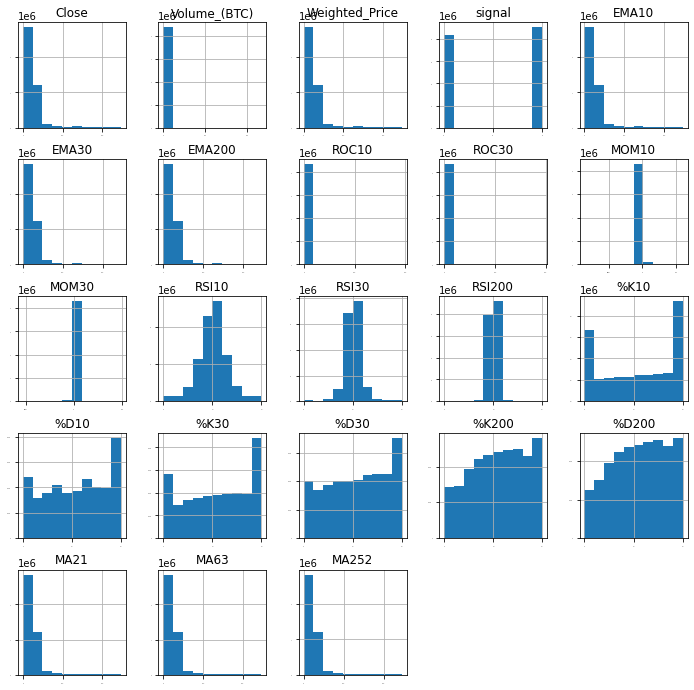
제시된 알고리즘 및 모델을 평가하기 위해서 먼저 데이터넷을 훈련하고, k-겹 교차 검증(k-folds cross validation)을 수행했습니다.
results = []
names = []
for name, model in models:
kfold = KFold(n_splits=num_folds, random_state=seed, shuffle=True)
cv_results = cross_val_score(model, X_train, Y_train, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std())
print(msg)
다음과 같은 결과가 나왔습니다. 앙상블 모델 중에서는 랜덤 포레스트가 최고의 성능을 보이는 것을 눈으로 확인할 수 있었습니다. 다만 구글 코랩으로 구글의 GPU를 사용했음에도 불구하고 무려 26분이나 시간이 걸렸습니다. 데이터가 무려 317메가바이트이기도 하고, 무려 9개의 모델을 비교 검증하는 것이다보니까 시간이 상당히 걸립니다. 제가 처음에는 아나콘다를 노트북에 설치해서 주피터 노트북으로 구동을 했는데, 노트북에 GPU가 없다보니 시간이 너무 오래 걸렸고, 결국 구글 코랩으로 옮기게 된 직접적인 이유이기도 합니다.
# compare algorithms
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
fig.set_size_inches(15,8)
plt.show()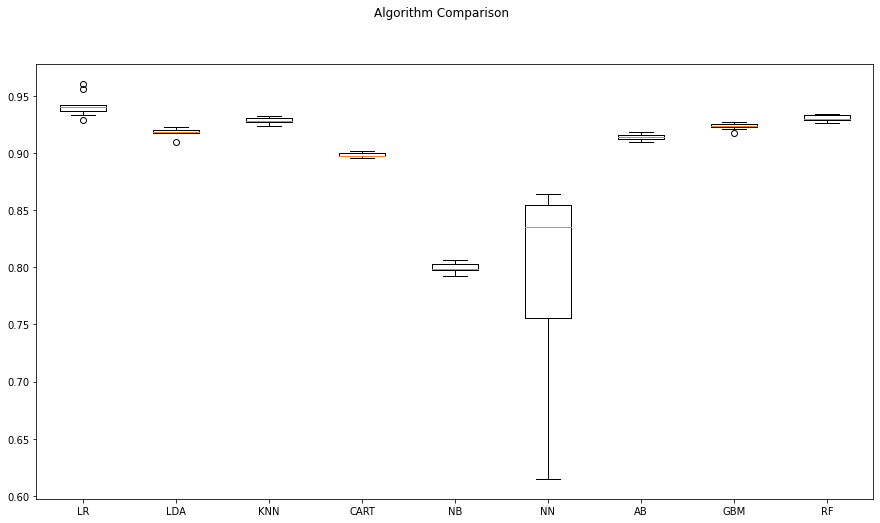
알고리즘 비교 결과를 matplotlib으로 시각화한 자료입니다. 한 눈에 각 모델의 수치를 비교할 수 있습니다.
이 실전 문제(비트코인 거래 전략)는 머신러닝으로 금융 문제를 해결할 때 문제를 구조화하는 것이 핵심 단계라는 것을 시연해 보였다. 이 과정에서 투자 목표에 따라 레이블을 변환하고 특성 엔지니어링을 수행하는 것이 거래 전략을 위해 필요하다는 것을 확인했다. 가격 움직임의 추세 및 모멘텀과 관련된 직관적인 특성을 사용하는 것이 효율적임을 입증했다. 이것은 모델의 예측력을 높이는 데 유용했다.
(중략)
이 장에 제시된 파이썬, 머신러닝, 금융의 개념은 금융의 다른 분류 기반 문제에 대한 청사진으로 사용할 수 있다.
-금융 전략을 위한 머신러닝 책 본문 229쪽
책에서 언급된 위의 내용에서처럼 금융과 관련된 개념을 비트코인 차트 분석과 같은 금융 사례를 통해 제시함으로써 금융 관련 실무를 수행하는데 있어서 발생하는 다양한 문제들을 해결하는데 큰 도움이 될 것입니다.이 장의 마지막에서는 다음의 연습 문제를 제공함으로써 독자로 하여금 더욱 깊이 있는 사례 연구를 해볼 수 있도록 돕습니다.

6. 신용카드 거래 사기 탐지 예제
https://gitlab.com/inspro9/hanbit_mlfi/-/blob/main/Ch6_SLC/CS1FD/FraudDetection.ipynb
Ch6_SLC/CS1FD/FraudDetection.ipynb · main · Hahnsang Kim / hanbit_mlfi
GitLab.com
gitlab.com
사기 탐지와 관련된 예제 중에서 가장 인상 깊었던 부분은 모델 튜닝이었습니다. 원하는 수준의 모델의 정확도를 얻을 때까지 지속적으로 개선하는 점은 저에게도 큰 도움이 되었습니다.
# Grid Search: GradientBoosting Tuning
'''
n_estimators : int (default=100)
The number of boosting stages to perform.
Gradient boosting is fairly robust to over-fitting so a large number usually results in better performance.
max_depth : integer, optional (default=3)
maximum depth of the individual regression estimators.
The maximum depth limits the number of nodes in the tree.
Tune this parameter for best performance; the best value depends on the interaction of the input variables.
'''
n_estimators = [20,180,1000]
max_depth= [2, 3,5]
param_grid = dict(n_estimators=n_estimators, max_depth=max_depth)
model = GradientBoostingClassifier()
kfold = KFold(n_splits=num_folds, random_state=seed, shuffle=True)
grid = GridSearchCV(estimator=model, param_grid=param_grid, scoring=scoring, cv=kfold)
grid_result = grid.fit(X_train_new, Y_train_new)
#Print Results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
ranks = grid_result.cv_results_['rank_test_score']
for mean, stdev, param, rank in zip(means, stds, params, ranks):
print("#%d %f (%f) with: %r" % (rank, mean, stdev, param))
신용카드 거래 사기 탐지는 신용카드 거래 불이행 비율을 발견하는 모델로 다양한 머신러닝 모델을 사용해보고, 적절한 평가 메트릭을 선택하고 불균형한 데이터를 어떻게 처리하는지를 시연하는지를 선보이고 있습니다.
7. NLP를 사용한 문서 요약 예제
https://gitlab.com/inspro9/hanbit_mlfi/-/blob/main/Ch10_NLP/CS3DS/DocumentSummarization.ipynb
Ch10_NLP/CS3DS/DocumentSummarization.ipynb · main · Hahnsang Kim / hanbit_mlfi
GitLab.com
gitlab.com
오늘 리뷰에서 마지막으로 살펴볼 예제는 NLP를 사용한 문서 요약 예제입니다. 금융 관련 문서를 자연어 처리를 통해서 핵심을 요약하여 요점을 빠르게 파악할 수 있도록 돕는 프로세스입니다. 사이킷런의 LDA로 문서 요약을 연습해보겠습니다.
#Libraries for pdf conversion
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
import re
from io import StringIO
#Libraries for feature extraction and topic modeling
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
#Other libraries
import numpy as np
import pandas as pdpdf 변환 라이브러리, 특성 추출 및 주제 모델링 라이브러리, 기타 라이브러리를 불렀습니다.
import mglearn
topics = mglearn.tools.print_topics(topics=range(1,6), feature_names=features,
sorting=array, topics_per_chunk=5, n_words=10)
mglearn으로 5가지 주제에서 상위 10개의 단어를 추출했습니다. 다음으로는 주제 시각화를 해보았습니다.
plt.figure(figsize=(16,13))
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.figure()
#plt.imshow(raw_pic, cmap=plt.cm.gray, interpolation='bilinear')
plt.axis("off")
plt.show()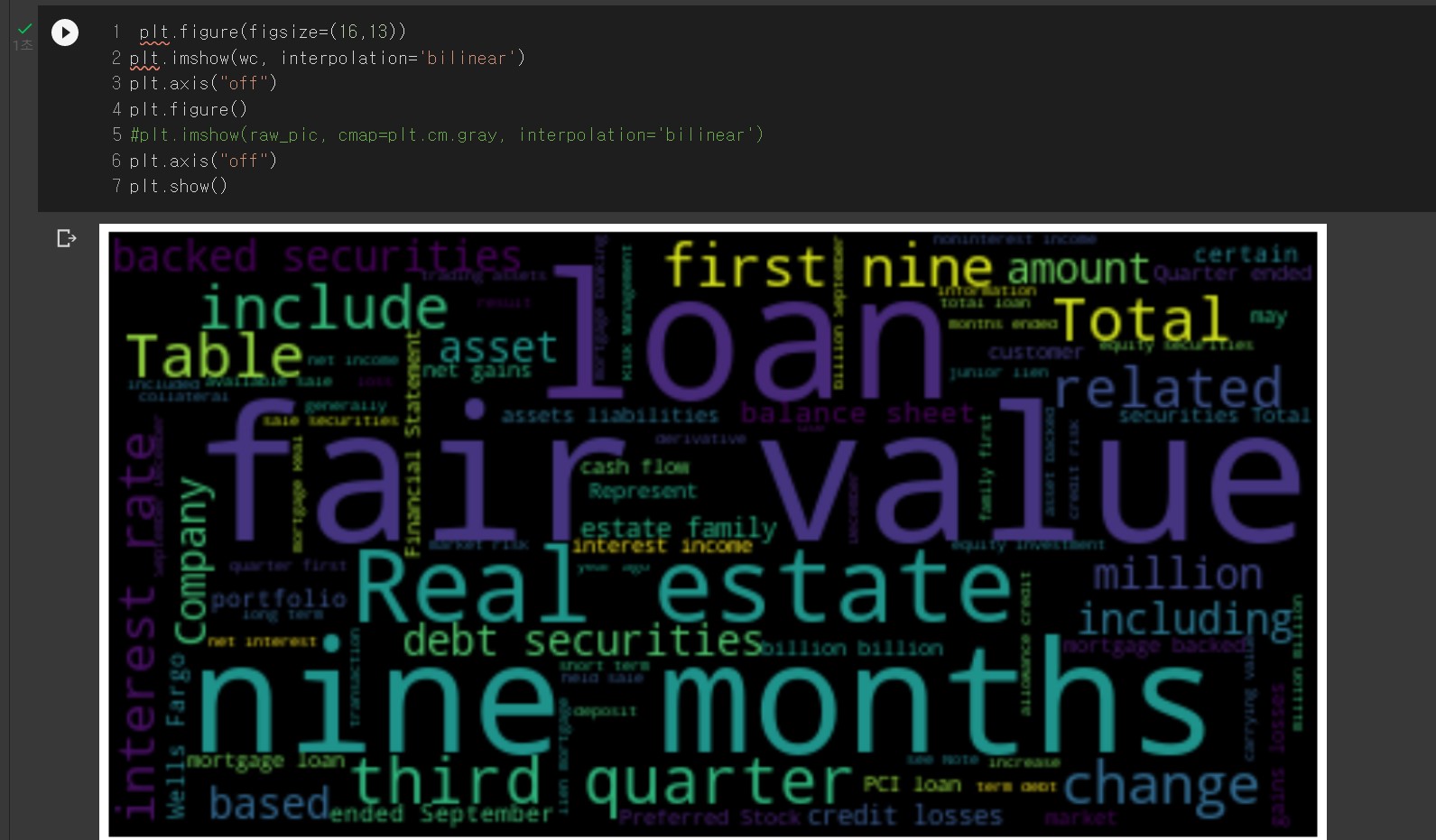
8. 금융 전략을 위한 머신러닝(Machine Learning and Data Science Blueprints for Finance) 리뷰를 마치며
2주 동안 금융 전략을 위한 머신러닝(Machine Learning and Data Science Blueprints for Finance)에 빠져 있었습니다. 왜 이 책의 원제에 Blueprints(청사진)이 들어 있을까? 생각을 많이 했는데, 다음의 이유에서 금융을 위한 머신러닝 청사진이 맞다고 생각했습니다.
- 7단계 문제 접근방법 템플릿
- 금융 분야의 핵심적인 19가지 사례
- 심도 있는 연습문제
이를 통해서 금융 분야의 머신러닝 전문가로 성장할 수 있는 구체적이고 완벽한 청사진을 제공하는 책입니다. 이 책을 모두 읽고 나니 금융 분야에서 실무자가 겪게될 대부분의 문제를 간접적으로 경험할 수 있었고, 문제를 해결하는 솔루션까지 학습할 수 있었습니다.
누구나 쉽게 접근할 수 있는 책은 아니지만, 머신러닝을 통해 금융 투자 전문가로 성장하고자 하는 독자 혹은 데이터 전문가로서 자신의 영역을 확장시키고자 하는 독자 모두에게 최고의 청사진을 제공하는 사례연구서입니다. 이 책을 통해서 대한민국의 금융 분야에도 머신러닝과 데이터 과학이 더욱 큰 기여를 하였으면 하는 바람입니다.
감사합니다.
어떠셨나요? 도움이 되셨나요?
그러면 다음에도 더욱 좋은 글로 돌아오겠습니다.
궁금한 사항 있으시면 댓글로 남겨주세요.
도움이 필요하시다면 사연을 적어서 이메일을 보내주세요.
그리고 도움이 되셨다면 공감과 구독 부탁드려요.
이상으로 동사힐이었습니다!
읽어주셔서 감사합니다. 😊
'북로그 > 독서 기록' 카테고리의 다른 글
| 삼국지 관우는 왜 조선에서 전쟁의 신이 되었을까?(feat. 만화로 배우는 조선 왕실의 신화 리뷰) (0) | 2022.02.24 |
|---|---|
| 데이터를 분석하고 시각화하는 아주 쉬운 방법(feat. 혼자 공부하는 R 데이터분석 리뷰) (0) | 2022.02.16 |
| 저는 주식투자가 처음인데요 리뷰(feat. 투자전략편을 읽고) (0) | 2022.02.03 |
| 아직도 주식 투자를 해보지 않았다면? (feat. 이 책부터 읽어보자.) (0) | 2022.01.26 |
| 왜 지금 슈퍼 석세스를 읽어야 할까?(feat. 신년을 준비하며 다시 읽는 슈퍼 석세스) (0) | 2022.01.04 |

댓글